뇌졸중 연구에서 자연어처리와 텍스트 마이닝의 적용
An Implementation of Natural Language Processing and Text Mining in Stroke Research
Article information
Trans Abstract
Natural language processing (NLP) is a computerized approach to analyzing text that explores how computers can be used to understand and manipulate natural language text or speech to do useful things. In healthcare field, these NLP techniques are applied in a variety of applications, ranging from evaluating the adequacy of treatment, assessing the presence of the acute illness, and the other clinical decision support. After converting text into computer-readable data through the text preprocessing process, an NLP can extract valuable information using the rule-based algorithm, machine learning, and neural network. We can use NLP to distinguish subtypes of stroke or accurately extract critical clinical information such as severity of stroke and prognosis of patients, etc. If these NLP methods are actively utilized in the future, they will be able to make the most of the electronic health records to enable optimal medical judgment.
서 론
정보기술과 데이터 저장 및 처리기술이 점차 고도화되면서, 의료영역에서도 환자와 관련된 수많은 데이터를 이용하여 환자의 치료를 최적화하거나 진단을 보조할 수 있는 시대가 되었다[1]. 그러나 이러한 정보의 홍수는 반대로 그만큼 환자를 치료하기 위해 확인해야 되는 정보의 양도 많아졌다는 것을 의미한다[2]. 쌓여가는 전자 의무기록(electronic medical record, EMR) 데이터 중에서 정형데이터가 차지하는 비중보다는 영상, 시그널 또는 텍스트와 같은 비정형데이터가 차지하는 비중이 월등이 높은데[3,4], 이렇게 방대한 비정형데이터를 일일이 확인하는 것은 불가능에 가깝다.
자연어처리(natural language process)는 인간의 언어 현상을 컴퓨터와 같은 기계를 이용해서 묘사할 수 있도록 연구하고, 이를 구현할 수 있도록 하는 인공지능의 주요 연구분야의 하나이다[5,6]. 여기서 자연어란 자연적으로 발생하여 사람들의 의사소통에 사용되는 언어로, C, R 또는 파이썬과 같은 컴퓨터 프로그래밍 언어와 같이 사람에 의해 의도적으로 만들어진 인공어(constructed language)에 대비되는 개념이다[7,8]. 즉 자연어는 한글, 영어와 같이 일상적인 의사소통을 위해 자연적으로 만들어진 언어로, 이러한 자연어를 컴퓨터가 이해하고, 기계가 읽을 수 있도록 가공 및 처리하는 일련의 과정을 자연어처리라고 한다[9]. 의료에 있어 이러한 자연어처리 기법은 치료의 적정성에 대한 평가, 질병의 이환 여부 평가 및 임상의사결정보조에 이르는 다양한 응용분야에 적용되고 있다[10]. 의학용어나 EMR 데이터로부터 특정 정보를 추출하는 자연어처리의 능력은 환자의 치료를 최적화하고 인간이 가질 수 있는 의학적 오류를 최소화할 수 있어, 정밀의학을 실현할 수 있는 기술의 핵심이자 가장 활발히 인공지능을 적용할 수 있는 분야이다.
혹자는 텍스트 마이닝과 자연어처리에 대한 정확한 구분을 요구할 수도 있다. 텍스트 마이닝은 텍스트 형태의 비정형데이터로부터 새로운 고급 정보를 이끌어내는 과정을 이야기하며, 이 경우에는 문서의 텍스트의 구조를 중요시하지 않는다[11]. 자연어처리의 경우에는 일반적으로 텍스트의 구조를 중요시하며, sentence splitting, part-of-speech tagging 또는 parse tree construction 등의 방법을 사용하여 텍스트로부터 문맥이나 의미를 찾아내는 과정이라고 이해할 수 있다[12]. 그러나 최근의 경우에는 자연어처리 방법을 이용한 텍스트 마이닝이 많이 사용되고 있어, 본문에서는 이러한 구분 없이 자연어처리로 기술하였다. 본 종설에서는 뇌졸중과 관련된 자연어처리 연구들을 정리하여 자연어처리에 대한 개념을 간단히 소개하고, 향후 뇌졸중 연구에서 자연어처리의 전망에 대해 기술하겠다.
본 론
1. 텍스트의 벡터화
1) 토큰과 텍스트벡터를 만들기 위한 자연어 전처리
환자들의 임상기록 및 방사선 보고서와 같이 텍스트로 이루어진 보고서를 기계가 읽도록 만들어 주는 과정을 전처리(preprocessing) 과정이라고 한다[13]. 여기에서 토큰(token)은 텍스트 분석의 기본이 되는 단위로 음절, 단어 구, 문장 등이 토큰의 단위가 될 수 있다. 가장 일반적으로는 한 단어를 토큰으로 하여 텍스트의 모든 내용을 토큰화하고, 대소문자 통일, 단어 어간추출(word stemming) 및 제외어 제거(stop word removal) 등을 거쳐 매트릭스(matrix) 형태의 벡터 데이터프레임을 형성하는 것이 텍스트 전처리 과정의 일반적인 과정이다(Fig. 1) [14]. 여기서 어간추출이라 함은 “artery, arterial, arterio” 등과 같이 같은 의미로 사용되고 있는 단어들의 기원인 “arter”로 토큰을 치환하는 것을 의미한다[15]. 또한 제외어는 텍스트벡터를 만들 때 키워드로 하지 않는 언어들로, 검색용어로 잘 사용하지 않는 “and, is, in, therefore”와 같은 관사, 전치사, 조사, 접속사 등 의미가 없는 단어들을 제거하는 과정이 제외어 제거과정에 해당한다[16].
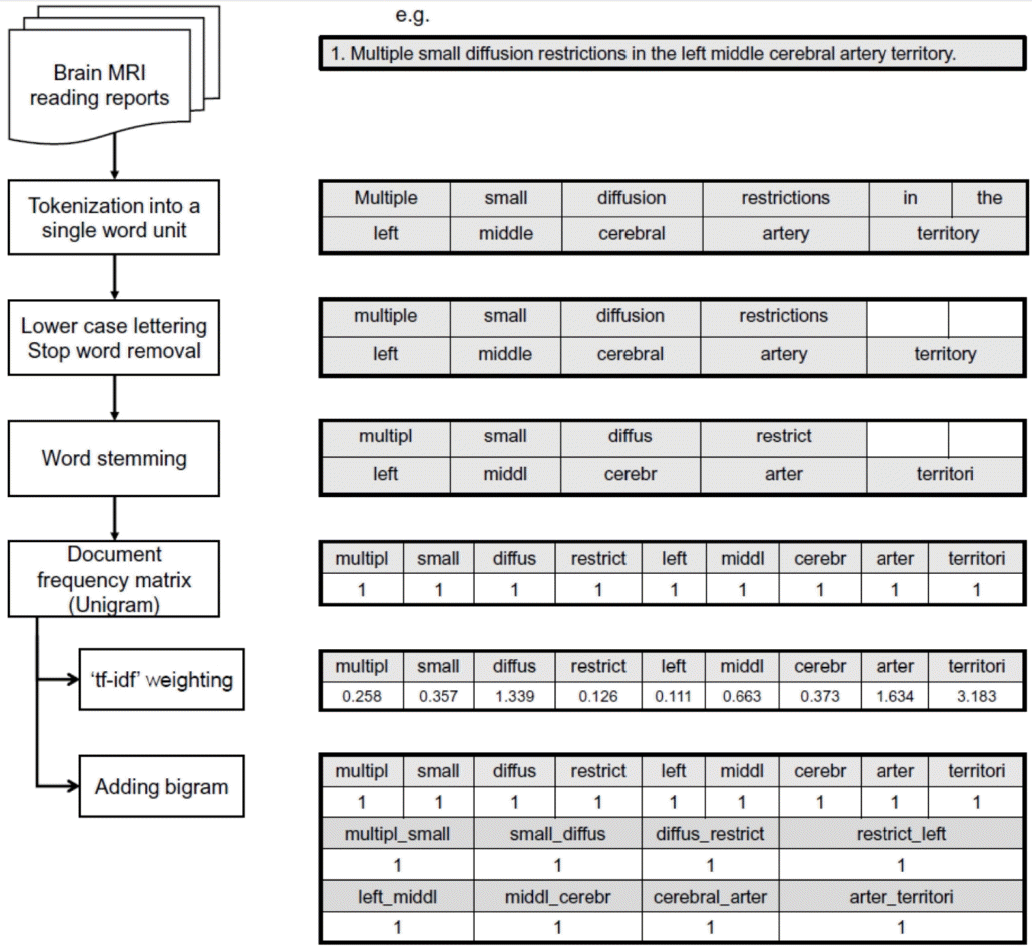
Natural language preprocessing flow chart for the corresponding texts. MRI; magnetic resonance imaging, tf-idf; term frequency inverse document frequency.
2) Concept mapping and rule-based mechanism
Concept mapping 방법은 가공하지 않은 원래의 텍스트로부터 중요한 개념을 뽑아내는 방법으로 MetaMap, MedLEE, cTAKES 등이 많이 사용되고 있다[17-21]. 간략하게는 concept mapping은 전처리된 텍스트로부터 이미 사전에 고유하게 등록되어 있는 중요한 의학용어들을 추출하는 방법을 말한다. MetaMap은 Aronson [19,22]에 의해 고안된 방법으로 Nation Library of Medicine에서 추출된 텍스트를 Unified Medical Language System Metathesaurus에 등록되어 있는 concept unique identifier가 있는 단어들로 매핑하는 방법이다. 이렇게 매핑되어 있는 identifier의 조합과 특별한 컴퓨터 언어학을 이용하여 해당 텍스트로부터 중요한 의미를 뽑아내는 방법 중의 하나이다.
3) 텍스트 임베딩
텍스트 임베딩이란 자연어를 벡터로 변환하는 기법을 말하는 것으로, 이는 텍스트를 벡터공간으로 “끼워넣는다(embed)”라는 의미에서 유래되었다. 즉 자연어를 기계가 이해할 수 있고 연산과 처리가 가능한 벡터로 바꾸게 되면, 문장의 의미를 계산할 수 있고 사칙연산이 가능하여 컴퓨터에게 의미나 문법적인 정보를 산술적으로 전달할 수 있게 된다[23]. 텍스트 분석의 단위를 말뭉치(corpus)라고 하는데[24], 이러한 말뭉치의 통계적인 패턴을 단어, 순서, 분포에 따라 임베딩을할 수 있다. 단어가 중심일 경우에는 “bag-of-words”라는 모델을 사용한다[25]. 여기서 “bag”이란 중복을 제외하지 않은 단어들의 집합을 얘기하고, Fig. 2에서와 같이 해당 말뭉치는 여러 토큰과 해당 토큰의 빈도로 구성된 데이터프레임 형태의 벡터로 만들어지게 된다[26]. 또한 n-gram이라는 것은 토큰들의 순서들까지 같이 고려하여 n개의 토큰을 순서대로 묶어 벡터를 만드는 것을 말한다[27]. 마지막으로 워드 임베딩(word embedding)이라는 방법은 어휘의 단어나 구문이 실제 숫자의 벡터에 매핑되는 자연어처리의 언어 모델링 및 기능 학습기법 중 하나로, 위키피티아 또는 네이버지식인과 같이 대량의 텍스트들의 단어들을 학습하여 수치형 벡터로 만드는 과정을 말한다[28,29]. 이렇게 학습을 하는 과정에는 현재 내가 관심이 있는 문장 또는 단어만을 학습시키는 “task-specific” 워드 임베딩 방법과 함께 앞서 기술한 위키피티아 또는 페이스북 등 잘 알려져 있는 텍스트 집합의 단어나 문장 전체를 학습하는 “pretrained” 워드 임베딩 방법이 있다[30,31].

Example natural language processing and machine learning of brain magnetic resonance imaging radiology text reports. ACA; anterior cerebral artery, R/O; rule out, ICA; internal carotid artery, LASSO; least absolute shrinkage and selection operator, SDT; single decision tree, RF; random forest, SVM; support vector machine.
2. 자연어처리 분석
해당되는 텍스트로부터 전처리 과정을 거쳐 컴퓨터가 읽을 수 있도록 한 이후, 우리는 자연어처리 과정을 통해 중요한 정보들을 추출할 수 있는데, 이러한 과정에는 크게 3가지 방법이 사용되고 있다. 첫째, 가장 오래 전부터 사용되고 있는 방법인 룰기반알고리즘(rule-based algorithm)은 정규식 표현이나 이미 정해져 있는 문맥자유문법(context free grammar)을 이용하여 패턴을 매칭하거나 비어 있는 결과 컬럼을 채워 넣은 형태로 정보들을 얻게 되는 경우이다[32]. 이러한 방법은 자료들을 학습시키지 않아도 된다는 장점이 있으나, 다른 데이터에 적용하기 위한 일반화에는 한계가 있을 수 있다. 둘째, 고전적인 머신러닝 방법이 이에 해당하는데, 로지스틱 회귀분석, 서포트벡터머신, 의사결정나무(decision tree) 등의 방법과 앙상블 머신러닝 방법인 랜덤 포레스트 및 extreme gradient boosting 등이 대표적인 방법이다[33,34]. 텍스트 데이터프레임을 이용하여 특정 표현형으로 구분하거나(classification), 특정 수치형 데이터를 산술적으로 예측(regression)하는 방법으로 이루어지며, 이를 통해 우리는 대량의 텍스트 데이터로부터 뇌경색 환자를 찾아내거나, 뇌졸중의 아형과 같은 특정 표현형을 찾아낼 수 있다. 세 번째로 뉴럴네트워크 방법은 머신러닝 방법과 유사한 방법이나 뉴런의 형태와 같은 층들을 다양하게 쌓아 벡터들의 가중치들을 종합하여 결과를 얻어내는 방법이다[35]. 이러한 뉴럴네트워크 방법은 단어들의 순서(sequence)를 인식할 수 있는 순서모델을 설계할 수 있어, 최근 자연어처리에서 고전적인 머신러닝 방법에 비해 더 많이 사용되고 있다[36]. 또한 자연어처리 분석에 있어 뉴럴네트워크가 고전적인 머신러닝 방법에 비해 일반적으로 성능이 훨씬 높은 것으로 보고되고 있어, 합성곱신경망(convolutional neural network), 순환신경망(recurrent neural network) 및 encoder-decoder 등의 뉴럴네트워크 방법이 많이 사용되고 있다[37].
3. 자연어처리 기반의 뇌졸중 연구
저자는 자연어를 이용하여 “PubMed”에 보고된 연구들의 방법 및 결과를 Table에 제시하였다. Elkins 등[38]은 The Northern Manhattan Study 데이터를 이용하여 computed tomography (CT)와 magnetic resonance imaging (MRI) 판독지를 규칙기반 알고리즘으로 분석하였다. 해당 텍스트 데이터에 뇌졸중 병변이 있는 것인지를 예측하기 위한 성능은 area under the receiver operating characteristics (AUROC) 85%로 높지는 않았으나, MedLEE를 이용한 첫 뇌졸중관련 자연어처리 연구로 자동적으로 CT나 MRI 판독지 텍스트를 이용하여 새로운 정보들을 자동적으로 추출해낼 수 있다는 것을 보인 첫 번째 연구이다. 이와 같이, 자연어처리의 적용은 다양한 목적을 위해 사용될 수 있는데, Pons 등[39]은 자연어처리 기반 연구의 목적을 1) 진단서베일런스, 2) 역학 연구를 위한 코호트 구축, 3) 영상검사의 질평가, 4) 임상의사결정지원시스템(clinical decision support system)으로 구분하였다. 진단서베일런스는 특정질환이나 급성 뇌경색과 같은 관심이 있는 특정 소견에 대한 정보를 자동적으로 얻는 것을 말한다. Mowery 등[40]은 경동맥초음파 판독지 및 임상경과 레포트를 PyConText 매핑을 이용하여 의미 있는 경동맥협착의 정보를 정확하게 얻을 수 있는지 조사하여, 민감도 73-88% 및 특이도 84-87%의 예측성능을 보고하였다. 또한 Kim 등[41]은 특정 MRI 판독지 데이터셋으로부터 급성기 뇌경색 환자들을 분류해낼 수 있는 자연어처리 기반의 머신러닝 연구 결과를 제시하였다. 3,204명의 MRI 판독지를 분석함에 있어 “bag-of-word” 모델과 n-gram이 성능에 미치는 결과를 분석하였는데, 단순한 “bag-of-word” 모델이 계산력이 필요한 n-gram 방법과 비교하여 성능이 크게 차이가 나지 않는다는 결과를 보여주었다[41]. 이와 같이 특정질환군을 판독지로부터 찾아낼 수 있는 자연어처리 방법은 코호트 연구나 역학 연구에서 환자군을 추출하는 데 있어 상당한 시간소모를 줄일 수 있다[42]. 자연어처리 방법을 이용한 영상검사의 질평가에 대한 뇌졸중 관련 연구에 대해 보고는 없었고, 나머지 연구들의 경우 대부분이 임상의사결정지원시스템에 대한 연구 결과였다. 이 임상의사결정지원시스템은 환자로 부터 얻어진 임상정보를 바탕으로 의료인이 질병을 진단하고 치료할 때 의사결정을 도와주는 시스템으로 정의한다. Ong 등[43]은 1,359개의 뇌CT, CT혈관조영검사 및 MR혈관조영검사의 판독지를 이용하여 판독지가 뇌경색이 있는지, 중대뇌동맥을 침범하였는지 그리고 급성 병변이 있는지를 예측할 수 있는지 조사하였다. 텍스트를 전처리하는 방법은 “bag-of-words” 모델부터 global vectors for word representation (GloVe) 임베딩 방법을 이용하였고, 자동분류기는 로지스틱회귀분석부터 RNN을 이용한 딥러닝 방법을 모두 적용하였다. 결과적으로 자동분류기의 성능은 GloVe 임베딩을 이용한 순환신경망 알고리즘의 성능이 허혈뇌졸중의 존재 여부, 중대뇌동맥 침범 여부 및 급성기 병변 유무를 예측하는 데 있어서 AUROC 0.93 이상의 성능을 보여주었다. 이와 같이 자연어처리를 이용한 딥러닝 방법을 통하여 급성기 병변의 유무 및 병변의 위치 등을 빠르고 정확하게 분류해낼 수 있는 자연어처리 방법은 비정형텍스트 데이터를 이용한 임상의사결정지원시스템에 많이 사용되고 있다. 이러한 텍스트 판독지를 이용하여 병변의 위치[38,43-45], 무증상 뇌경색46의 여부와 같은 방사선 표지자를 찾은 연구와 더불어, 자연어처리를 임상기록까지 포함하여 분석할 경우 혈관기원의 일과성 뇌허혈에 대한 구분[47], 뇌졸중의 아형[48,49], 적절한 정맥혈전용해제 사용을 위한 적응증 및 금기증 확인[50], 뇌졸중 심각도[51] 및 뇌졸중 3개월 이후의 예후[52] 등의 다양한 표현형을 예측하는 데 있어 빠르고 정확한 임상결 정보조정보를 제공할 수 있다. 그러나 현재까지는 텍스트 머신러닝의 성능 또한 개선되어야 할 부분이 있어 텍스트 딥러닝의 활발한 사용을 위해서는 택스트 전처리 방법 및 알고리즘의 고도화가 요구되고 있다.

Studies of natural language processing-based stroke research
다른 인공지능 연구분야에 비해 자연어처리 연구에 있어서 더욱 중요한 사항은 개발된 알고리즘에 대한 외부타당도 검사이다. Digital image and communication in medicine 영상이나 심전도의 파형과 같은 시그널 정보와 같이 비교적 정형화된 툴을 기반을 데이터가 수집된 경우에는 고유의 데이터로 개발된 인공지능 파이프 라인이 예측이 필요한 다른 데이터(unseen data)에 적용하기 용이하지만, 텍스트라는 것은 판독지나 임상경과기록지가 개인의 성향을 반영한 결과물이며, 구조화되어 있지 않은 자유로운 형태이기 때문에, 개발된 텍스트 기반 알고리즘의 일반화된 성능을 검사하기 위해서는 외부적인 타당성 검사가 반드시 필요하다. 본 뇌졸중 관련 연구들 중에서 이러한 외부타당도가 시행된 연구는 3개의 연구로[42,43,45], 자연어처리 관련 연구를 해석하고 적용하는 데 있어 이러한 외적 타당도에 대한 증명이 완료된 알고리즘인지를 확인하는 것은 매우 중요하다.
또한 Table에서 시행된 연구들에서는 알고리즘의 성능을 향상시키기 위해 k겹 교차검증(k-fold cross-validation)이 사용되었다.이 k겹 교차검증은 모델의 학습 및 검증에 사용되는 데이터를 k개로 나누어서 검증과 평가를 시행하는 것을 말한다(Fig. 3). 전체의 데이터는 학습데이터와 검증데이터로 나뉘게 되는데, 이 학습데이터를 k개로 분할한 이후에 k-1개의 겹데이터는 학습에 사용되고 1개의 겹데이터는 알고리즘의 내부타당도를 확인하기 위해 사용되며, 학습이 k번으로 반복이 되면서 학습용데이터로 계발된 알고리즘의 과적합을 최소화할 수 있다[53].
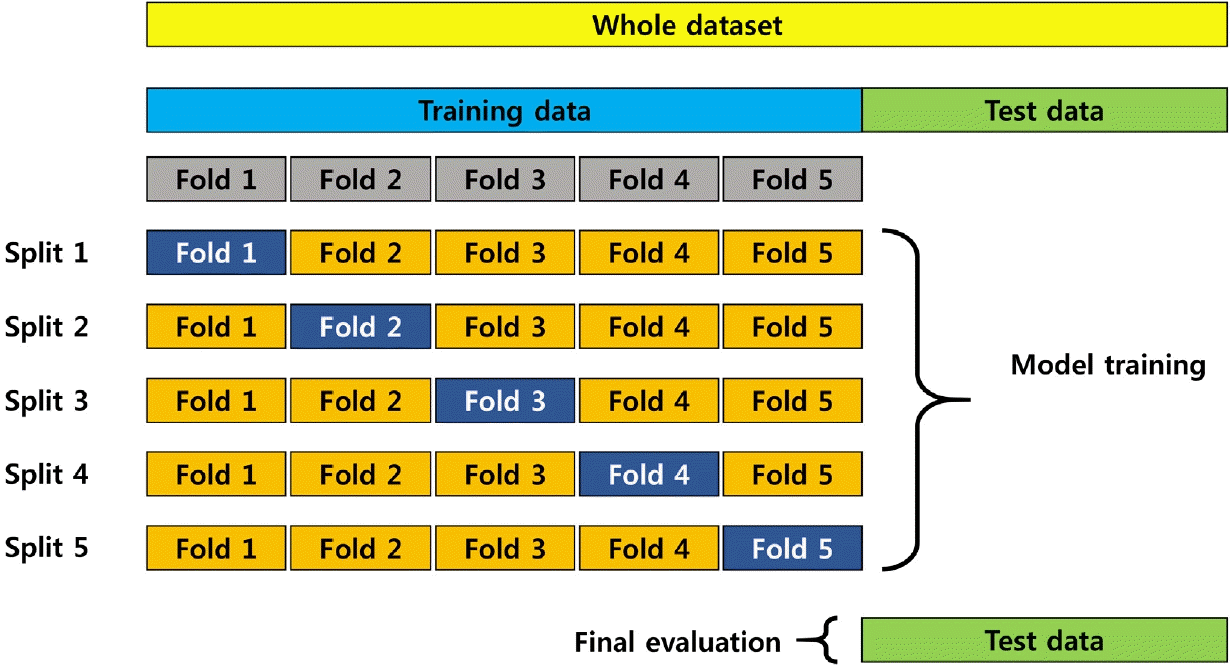
Example of 5-fold cross-validation in machine learning.
EMR의 텍스트 머신러닝 분석을 할 때 반드시 고려해야 할 사항은 다루어야 할 텍스트의 종류이다. 대부분의 국내 EMR 기록의 경우 한글과 영문이 혼재되어 사용되고 있다. 철자오류는 많은 데이터를 이용하여 충분히 오류를 극복할 수 있으나 이러한 이중언어문제(bilingualism)는 텍스트 전처리 과정에서 한글 또는 영문만을 따로 전처리할 수밖에 없어 필연적으로 정보의 손실을 가져올 수 있다. 또한 한글의 형태소 분석기의 경우 한글의학용어를 충분히 반영하고 있지 않기 때문에 한영혼재 EMR 기록의 효과적인 전처리는 EMR 자연어처리 분야에서 여전히 해결해야 할 과제 중의 하나이다. 한영혼재 텍스트를 기반으로 한 pretrained word embedding 방법 또는 “네이버지식인”과 같은 한글의학용어의 문장들을 크롤링하여 새로운 의학사전을 만드는 방법 등을 시도해볼 수 있으나 아직까지 개발단계는 미흡한 상황이므로 이러한 한영혼재 EMR 데이터를 다룰 때에는 세심한 주의가 필요하다.
결 론
뇌졸중 대상의 자연어처리 연구가 이제 본격적으로 시작되고 있다. 우리는 자연어처리 방법을 통하여 EMR의 상당부분을 차지하고 있는 비정형텍스트 데이터를 벡터화하고, 컴퓨터가 읽어 들여 자동적으로 중요한 정보를 추출해낼 수 있는 인공지능 알고리즘을 효과적으로 적용할 수 있다. 자연어처리를 통한 기계학습은 인간이 하지 못하는 방대한 정보를 목적에 따라 구분하고, 환자들의 임상경과를 최적화할 수 있는 임상의사결정보조시스템으로 점차 진화할 것이다.